sqlite-utils 命令行工具¶
sqlite-utils 命令行工具可用于通过多种不同方式操作 SQLite 数据库。
一旦安装,该工具应可作为 sqlite-utils 使用。它也可以使用 python -m sqlite_utils 运行。
运行 SQL 查询¶
sqlite-utils query 命令允许您直接对 SQLite 数据库文件运行查询。这是默认的子命令,因此以下两个示例的工作方式相同:
sqlite-utils query dogs.db "select * from dogs"
sqlite-utils dogs.db "select * from dogs"
注意
在 Python 中: db.query() CLI 参考: sqlite-utils query
返回 JSON¶
查询返回的默认格式是 JSON。
sqlite-utils dogs.db "select * from dogs"
[{"id": 1, "age": 4, "name": "Cleo"},
{"id": 2, "age": 2, "name": "Pancakes"}]
换行符分隔的 JSON¶
使用 --nl 以获取换行符分隔的 JSON 对象:
sqlite-utils dogs.db "select * from dogs" --nl
{"id": 1, "age": 4, "name": "Cleo"}
{"id": 2, "age": 2, "name": "Pancakes"}
JSON 数组¶
您可以使用 --arrays 来请求数组而不是对象:
sqlite-utils dogs.db "select * from dogs" --arrays
[[1, 4, "Cleo"],
[2, 2, "Pancakes"]]
您还可以组合使用 --arrays 和 --nl:
sqlite-utils dogs.db "select * from dogs" --arrays --nl
[1, 4, "Cleo"]
[2, 2, "Pancakes"]
如果您想进一步美化输出,可以通过 python -mjson.tool 管道处理它:
sqlite-utils dogs.db "select * from dogs" | python -mjson.tool
[
{
"id": 1,
"age": 4,
"name": "Cleo"
},
{
"id": 2,
"age": 2,
"name": "Pancakes"
}
]
JSON 中的二进制数据¶
二进制字符串不是有效的 JSON,因此包含二进制数据的 BLOB 列将以包含 base64 编码数据的 JSON 对象形式返回,如下所示:
sqlite-utils dogs.db "select name, content from images" | python -mjson.tool
[
{
"name": "transparent.gif",
"content": {
"$base64": true,
"encoded": "R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7"
}
}
]
嵌套的 JSON 值¶
如果您的某个列包含 JSON,默认情况下它将作为转义字符串返回:
sqlite-utils dogs.db "select * from dogs" | python -mjson.tool
[
{
"id": 1,
"name": "Cleo",
"friends": "[{\"name\": \"Pancakes\"}, {\"name\": \"Bailey\"}]"
}
]
您可以使用 --json-cols 选项自动检测这些 JSON 列,并将它们作为嵌套的 JSON 数据输出:
sqlite-utils dogs.db "select * from dogs" --json-cols | python -mjson.tool
[
{
"id": 1,
"name": "Cleo",
"friends": [
{
"name": "Pancakes"
},
{
"name": "Bailey"
}
]
}
]
返回 CSV 或 TSV¶
您可以使用 --csv 选项以 CSV 格式返回结果:
sqlite-utils dogs.db "select * from dogs" --csv
id,age,name
1,4,Cleo
2,2,Pancakes
这将默认为包含列名作为标题行。要排除标题,请使用 --no-headers:
sqlite-utils dogs.db "select * from dogs" --csv --no-headers
1,4,Cleo
2,2,Pancakes
使用 --tsv 代替 --csv 来获取 Tab 分隔值:
sqlite-utils dogs.db "select * from dogs" --tsv
id age name
1 4 Cleo
2 2 Pancakes
表格格式输出¶
您可以使用 --table 选项(或 -t 快捷方式)以表格形式输出查询结果:
sqlite-utils dogs.db "select * from dogs" --table
id age name
---- ----- --------
1 4 Cleo
2 2 Pancakes
您可以使用 --fmt 选项指定不同的表格格式,例如 reStructuredText 的 rst:
sqlite-utils dogs.db "select * from dogs" --fmt rst
==== ===== ========
id age name
==== ===== ========
1 4 Cleo
2 2 Pancakes
==== ===== ========
可用的 --fmt 选项有:
asciidocdouble_griddouble_outlinefancy_gridfancy_outlinegithubgridheavy_gridheavy_outlinehtmljiralatexlatex_booktabslatex_longtablelatex_rawmediawikimixed_gridmixed_outlinemoinmoinorgtbloutlinepipeplainprestoprettypsqlrounded_gridrounded_outlinerstsimplesimple_gridsimple_outlinetextiletsvunsafehtmlyoutrack
通过运行 sqlite-utils query --help 也可以找到此列表。
返回原始数据,如二进制内容¶
如果您的表在 BLOB 列中包含二进制数据,可以使用 --raw 选项将特定列直接输出到标准输出。
例如,要从 BLOB 列中检索二进制图像并将其存储到文件中,可以使用以下命令:
sqlite-utils photos.db "select contents from photos where id=1" --raw > myphoto.jpg
要以换行符分隔的原始数据形式返回每个结果的第一列,请使用 --raw-lines:
sqlite-utils photos.db "select caption from photos" --raw-lines > captions.txt
使用命名参数¶
您可以使用 -p 向查询传递命名参数:
sqlite-utils query dogs.db "select :num * :num2" -p num 5 -p num2 6
[{":num * :num2": 30}]
这些参数将在 SQL 查询中正确引用和转义,提供了一种将其他值与 SQL 结合的安全方法。
UPDATE、INSERT 和 DELETE¶
如果您执行 UPDATE、INSERT 或 DELETE 查询,命令将返回受影响的行数:
sqlite-utils dogs.db "update dogs set age = 5 where name = 'Cleo'"
[{"rows_affected": 1}]
定义自定义 SQL 函数¶
您可以使用 --functions 选项传递一段 Python 代码,该代码定义了可以由您的 SQL 查询调用的附加函数。
此示例定义了一个从 URL 提取域名的函数:
sqlite-utils query sites.db "select url, domain(url) from urls" --functions '
from urllib.parse import urlparse
def domain(url):
return urlparse(url).netloc
'
该块中定义的每个可调用对象都将注册为同名的 SQL 函数,以双下划线开头的函数除外。
SQLite 扩展¶
您可以使用 --load-extension 选项加载 SQLite 扩展模块,参见加载 SQLite 扩展。
sqlite-utils dogs.db "select spatialite_version()" --load-extension=spatialite
[{"spatialite_version()": "4.3.0a"}]
附加其他数据库¶
SQLite 支持跨数据库 SQL 查询,可以连接来自多个数据库文件表中的数据。
您可以使用 --attach 选项附加一个或多个其他数据库,为该数据库提供一个别名,并提供磁盘上 SQLite 文件的路径。
此示例将 books.db 数据库附加到别名 books 下,然后运行一个查询,该查询将该数据库中的数据与默认的 dogs.db 数据库中的数据相结合:
sqlite-utils dogs.db --attach books books.db \
'select * from sqlite_master union all select * from books.sqlite_master'
注意
在 Python 中: db.attach()
直接使用内存数据库查询数据¶
sqlite-utils memory 命令的工作方式类似于 sqlite-utils query,但允许您对内存数据库执行查询。
您还可以将 CSV 或 JSON 文件传递给此命令,这些文件将加载到临时内存表中,从而允许您直接对该数据执行 SQL,而无需先将其转换为 SQLite 的单独步骤。
不带任何额外参数时,此命令直接对内存数据库执行 SQL:
sqlite-utils memory 'select sqlite_version()'
[{"sqlite_version()": "3.35.5"}]
它接受与 sqlite-utils query 相同的输出格式选项:--csv、--csv、--table 和 --nl。
sqlite-utils memory 'select sqlite_version()' --csv
sqlite_version()
3.35.5
sqlite-utils memory 'select sqlite_version()' --fmt grid
+--------------------+
| sqlite_version() |
+====================+
| 3.35.5 |
+--------------------+
直接对 CSV 或 JSON 运行查询¶
如果您有 CSV 或 JSON 格式的数据,可以将其加载到内存 SQLite 数据库中,并使用 sqlite-utils memory 在一个命令中直接对其运行查询,如下所示:
sqlite-utils memory data.csv "select * from data"
如果您想对来自不同文件的数据进行连接,可以将多个文件传递给命令:
sqlite-utils memory one.csv two.json \
"select * from one join two on one.id = two.other_id"
如果您的数据是 JSON,其格式应与 sqlite-utils insert command 支持的格式相同 - 即单个 JSON 对象(被视为单行)或 JSON 对象的列表。
CSV 数据可以是逗号或 Tab 分隔的。
内存表将以文件名(不含扩展名)命名。该工具还会为这些表设置别名(使用 SQL 视图),如 t1、t2 等,或者您可以使用别名 t 指代第一个表:
sqlite-utils memory example.csv "select * from t"
如果两个文件具有相同的名称,将为其分配数字后缀:
sqlite-utils memory foo/data.csv bar/data.csv "select * from data_2"
要从标准输入读取,将 - 或 stdin 用作文件名 - 然后使用 stdin、t 或 t1 作为表名:
cat example.csv | sqlite-utils memory - "select * from stdin"
传入的 CSV 数据将假定使用 utf-8 编码。如果您的数据使用不同的字符编码,可以使用 --encoding 指定:
cat example.csv | sqlite-utils memory - "select * from stdin" --encoding=latin-1
如果您连接多个 CSV 文件,它们必须使用相同的编码。
CSV 或 TSV 数据中的列类型将自动检测,使用与 插入 CSV 或 TSV 数据 中描述的 --detect-types 相同的机制。您可以传递 --no-detect-types 选项来禁用此自动类型检测,并将所有 CSV 和 TSV 列视为 TEXT。
显式指定格式¶
默认情况下,sqlite-utils memory 将尝试自动检测传入的数据格式(JSON、TSV 或 CSV)。
您也可以通过在文件名后添加 :csv、:tsv、:json 或 :nl(用于换行符分隔的 JSON)后缀来显式指定格式。例如:
sqlite-utils memory one.dat:csv two.dat:nl \
"select * from one union select * from two"
这里,one.dat 的内容将被视为 CSV,two.dat 的内容将被视为换行符分隔的 JSON。
要显式指定通过标准输入管道传递给工具的数据格式,请使用 stdin:format - 例如:
cat one.dat | sqlite-utils memory stdin:csv "select * from stdin"
使用 --attach 将内存数据与现有数据库进行连接¶
attach 选项 可用于将数据库文件附加到内存连接,从而实现从文件加载的内存数据与现有 SQLite 数据库文件中表之间的连接。一个例子:
echo "id\n1\n3\n5" | sqlite-utils memory - --attach trees trees.db \
"select * from trees.trees where rowid in (select id from stdin)"
这里,--attach trees trees.db 选项使得 trees.db 数据库可以使用别名 trees。
select * from trees.trees where ... 然后可以查询该数据库中的 trees 表。
通过管道传递到脚本中的 CSV 数据在 stdin 表中可用,因此可以使用 ... where rowid in (select id from stdin) 返回与通过 CSV 内容管道传递的 ID 匹配的 trees 表中的行。
--schema、--analyze、--dump 和 --save¶
要查看将用于一个或多个文件的内存数据库 schema,请使用 --schema:
sqlite-utils memory dogs.csv --schema
CREATE TABLE [dogs] (
[id] INTEGER,
[age] INTEGER,
[name] TEXT
);
CREATE VIEW t1 AS select * from [dogs];
CREATE VIEW t AS select * from [dogs];
您可以使用 --analyze 运行与 analyze-tables 命令等效的操作:
sqlite-utils memory dogs.csv --analyze
dogs.id: (1/3)
Total rows: 2
Null rows: 0
Blank rows: 0
Distinct values: 2
dogs.name: (2/3)
Total rows: 2
Null rows: 0
Blank rows: 0
Distinct values: 2
dogs.age: (3/3)
Total rows: 2
Null rows: 0
Blank rows: 0
Distinct values: 2
您可以使用 --dump 输出将创建表并插入用于填充内存数据库的完整数据的 SQL:
sqlite-utils memory dogs.csv --dump
BEGIN TRANSACTION;
CREATE TABLE [dogs] (
[id] INTEGER,
[age] INTEGER,
[name] TEXT
);
INSERT INTO "dogs" VALUES('1','4','Cleo');
INSERT INTO "dogs" VALUES('2','2','Pancakes');
CREATE VIEW t1 AS select * from [dogs];
CREATE VIEW t AS select * from [dogs];
COMMIT;
传递 --save other.db 将转而使用该 SQL 来填充一个新的数据库文件:
sqlite-utils memory dogs.csv --save dogs.db
这些功能主要用作调试工具 - 有关如何将数据插入 SQLite 数据库文件的更精细控制,请参阅插入 JSON 数据和插入 CSV 或 TSV 数据。
返回表中的所有行¶
您可以使用 rows 命令返回指定表中的每一行:
sqlite-utils rows dogs.db dogs
[{"id": 1, "age": 4, "name": "Cleo"},
{"id": 2, "age": 2, "name": "Pancakes"}]
此命令接受与 query 相同的输出选项 - 因此您可以传递 --nl、--csv、--tsv、--no-headers、--table 和 --fmt。
您可以使用 -c 选项指定要返回的列子集:
sqlite-utils rows dogs.db dogs -c age -c name
[{"age": 4, "name": "Cleo"},
{"age": 2, "name": "Pancakes"}]
您可以使用 --where 选项使用 where 子句过滤行:
sqlite-utils rows dogs.db dogs -c name --where 'name = "Cleo"'
[{"name": "Cleo"}]
或者将命名参数与 --where 结合使用 -p:
sqlite-utils rows dogs.db dogs -c name --where 'name = :name' -p name Cleo
[{"name": "Cleo"}]
您可以使用 --order column 或 --order 'column desc' 定义排序顺序。
使用 --limit N 只返回前 N 行。使用 --offset N 从指定偏移量开始返回行。
注意
在 Python 中: table.rows CLI 参考: sqlite-utils rows
列出表¶
您可以使用 tables 命令列出数据库中的表名:
sqlite-utils tables mydb.db
[{"table": "dogs"},
{"table": "cats"},
{"table": "chickens"}]
您可以使用 --csv 或 --tsv 选项将此列表输出为 CSV:
sqlite-utils tables mydb.db --csv --no-headers
dogs
cats
chickens
如果您只想查看 FTS4 表,可以使用 --fts4(或 FTS5 表的 --fts5):
sqlite-utils tables docs.db --fts4
[{"table": "docs_fts"}]
使用 --counts 包含每个表中行数的计数:
sqlite-utils tables mydb.db --counts
[{"table": "dogs", "count": 12},
{"table": "cats", "count": 332},
{"table": "chickens", "count": 9}]
使用 --columns 包含每个表中列的列表:
sqlite-utils tables dogs.db --counts --columns
[{"table": "Gosh", "count": 0, "columns": ["c1", "c2", "c3"]},
{"table": "Gosh2", "count": 0, "columns": ["c1", "c2", "c3"]},
{"table": "dogs", "count": 2, "columns": ["id", "age", "name"]}]
使用 --schema 包含每个表的 schema:
sqlite-utils tables dogs.db --schema --table
table schema
------- -----------------------------------------------
Gosh CREATE TABLE Gosh (c1 text, c2 text, c3 text)
Gosh2 CREATE TABLE Gosh2 (c1 text, c2 text, c3 text)
dogs CREATE TABLE [dogs] (
[id] INTEGER,
[age] INTEGER,
[name] TEXT)
--nl、--csv、--tsv、--table 和 --fmt 选项也可用。
注意
在 Python 中: db.tables or db.table_names() CLI 参考: sqlite-utils tables
列出视图¶
views 命令显示数据库中定义的任何视图:
sqlite-utils views sf-trees.db --table --counts --columns --schema
view count columns schema
--------- ------- -------------------- --------------------------------------------------------------
demo_view 189144 ['qSpecies'] CREATE VIEW demo_view AS select qSpecies from Street_Tree_List
hello 1 ['sqlite_version()'] CREATE VIEW hello as select sqlite_version()
它接受与 tables 命令相同的选项:
--columns--schema--counts--nl--csv--tsv--table
注意
在 Python 中: db.views or db.view_names() CLI 参考: sqlite-utils views
列出索引¶
indexes 命令列出为数据库配置的任何索引:
sqlite-utils indexes covid.db --table
table index_name seqno cid name desc coll key
-------------------------------- ------------------------------------------------------ ------- ----- ----------------- ------ ------ -----
johns_hopkins_csse_daily_reports idx_johns_hopkins_csse_daily_reports_combined_key 0 12 combined_key 0 BINARY 1
johns_hopkins_csse_daily_reports idx_johns_hopkins_csse_daily_reports_country_or_region 0 1 country_or_region 0 BINARY 1
johns_hopkins_csse_daily_reports idx_johns_hopkins_csse_daily_reports_province_or_state 0 2 province_or_state 0 BINARY 1
johns_hopkins_csse_daily_reports idx_johns_hopkins_csse_daily_reports_day 0 0 day 0 BINARY 1
ny_times_us_counties idx_ny_times_us_counties_date 0 0 date 1 BINARY 1
ny_times_us_counties idx_ny_times_us_counties_fips 0 3 fips 0 BINARY 1
ny_times_us_counties idx_ny_times_us_counties_county 0 1 county 0 BINARY 1
ny_times_us_counties idx_ny_times_us_counties_state 0 2 state 0 BINARY 1
它显示所有表的索引。要查看特定表的索引,请在数据库名称后面列出这些表:
sqlite-utils indexes covid.db johns_hopkins_csse_daily_reports --table
该命令默认只显示明确属于索引的列。要同时包含辅助列,请使用 --aux 选项 - 这些列将列出 key 为 0。
该命令接受与 tables 和 views 命令相同的格式选项。
注意
在 Python 中: table.indexes CLI 参考: sqlite-utils indexes
列出触发器¶
triggers 命令显示为数据库配置的任何触发器:
sqlite-utils triggers global-power-plants.db --table
name table sql
--------------- --------- -----------------------------------------------------------------
plants_insert plants CREATE TRIGGER [plants_insert] AFTER INSERT ON [plants]
BEGIN
INSERT OR REPLACE INTO [_counts]
VALUES (
'plants',
COALESCE(
(SELECT count FROM [_counts] WHERE [table] = 'plants'),
0
) + 1
);
END
它默认为所有表显示触发器。要查看一个或多个特定表的触发器,请将它们的名称作为参数传递:
sqlite-utils triggers global-power-plants.db plants
该命令接受与 tables 和 views 命令相同的格式选项。
注意
在 Python 中: table.triggers or db.triggers CLI 参考: sqlite-utils triggers
显示 schema¶
sqlite-utils schema 命令显示数据库的完整 SQL schema:
sqlite-utils schema dogs.db
CREATE TABLE "dogs" (
[id] INTEGER PRIMARY KEY,
[name] TEXT
);
这将显示数据库中每个表和索引的 schema。要仅查看指定表子集的 schema,请将它们作为附加参数传递:
sqlite-utils schema dogs.db dogs chickens
注意
在 Python 中: table.schema 或 db.schema CLI 参考: sqlite-utils schema
分析表¶
使用新数据库时,了解数据的形态可能很有用。sqlite-utils analyze-tables 命令检查指定的表(或所有表),并计算这些表中每个列的一些有用详细信息。
要检查 github.db 数据库中的 tags 表,请运行以下命令:
sqlite-utils analyze-tables github.db tags
tags.repo: (1/3)
Total rows: 261
Null rows: 0
Blank rows: 0
Distinct values: 14
Most common:
88: 107914493
75: 140912432
27: 206156866
Least common:
1: 209590345
2: 206649770
2: 303218369
tags.name: (2/3)
Total rows: 261
Null rows: 0
Blank rows: 0
Distinct values: 175
Most common:
10: 0.2
9: 0.1
7: 0.3
Least common:
1: 0.1.1
1: 0.11.1
1: 0.1a2
tags.sha: (3/3)
Total rows: 261
Null rows: 0
Blank rows: 0
Distinct values: 261
对于每一列,此工具显示空行的数量、空白行(包含空字符串的行)的数量、不同值的数量,以及对于非完全不同的列,最常见和最不常见的值。
如果您未指定任何表,则将分析数据库中的所有表:
sqlite-utils analyze-tables github.db
如果您希望分析一个或多个特定列,请使用 -c 选项:
sqlite-utils analyze-tables github.db tags -c sha
要显示超过 10 个常见值,请使用 --common-limit 20。要跳过最常见或最不常见值的分析,请使用 --no-most 或 --no-least。
sqlite-utils analyze-tables github.db tags --common-limit 20 --no-least
保存分析后的表详细信息¶
对于大型数据库文件,analyze-tables 运行可能需要相当长的时间。您可以使用 --save 选项将分析结果保存到名为 _analyze_tables_ 的数据库表中:
sqlite-utils analyze-tables github.db --save
_analyze_tables_ 表具有以下 schema:
CREATE TABLE [_analyze_tables_] (
[table] TEXT,
[column] TEXT,
[total_rows] INTEGER,
[num_null] INTEGER,
[num_blank] INTEGER,
[num_distinct] INTEGER,
[most_common] TEXT,
[least_common] TEXT,
PRIMARY KEY ([table], [column])
);
most_common 和 least_common 列将包含嵌套的 JSON 数组,这些数组包含最常见和最不常见的值,如下所示:
[
["Del Libertador, Av", 5068],
["Alberdi Juan Bautista Av.", 4612],
["Directorio Av.", 4552],
["Rivadavia, Av", 4532],
["Yerbal", 4512],
["Cosquín", 4472],
["Estado Plurinacional de Bolivia", 4440],
["Gordillo Timoteo", 4424],
["Montiel", 4360],
["Condarco", 4288]
]
创建一个空数据库¶
您可以使用 create-database 命令创建一个新的空数据库文件:
sqlite-utils create-database empty.db
要在新创建的数据库上启用 WAL mode,添加 --enable-wal 选项:
sqlite-utils create-database empty.db --enable-wal
要在新创建的数据库上启用 SpatiaLite 元数据,添加 --init-spatialite 标志:
sqlite-utils create-database empty.db --init-spatialite
这将在一组可预测的位置查找 SpatiaLite。要从其他地方加载它,请使用 --load-extension 选项:
sqlite-utils create-database empty.db --init-spatialite --load-extension /path/to/spatialite.so
插入 JSON 数据¶
如果您有 JSON 数据,可以使用 sqlite-utils insert tablename 将其插入到数据库中。如果表不存在,将根据检测到的正确列创建表。
您可以传递单个 JSON 对象或 JSON 对象列表,作为文件名或直接通过管道传递到标准输入(通过使用 - 作为文件名)。
这是最简单的示例:
echo '{"name": "Cleo", "age": 4}' | sqlite-utils insert dogs.db dogs -
要指定列作为主键,请使用 --pk=column_name。
要创建跨多个列的复合主键,请多次使用 --pk。
如果您向其馈送 JSON 列表,它将插入多条记录。例如,如果 dogs.json 看起来像这样:
[
{
"id": 1,
"name": "Cleo",
"age": 4
},
{
"id": 2,
"name": "Pancakes",
"age": 2
},
{
"id": 3,
"name": "Toby",
"age": 6
}
]
您可以将所有三条记录导入到自动创建的 dogs 表中,并将 id 列设置为主键,如下所示:
sqlite-utils insert dogs.db dogs dogs.json --pk=id
多次传递 --pk 以定义复合主键。
您可以使用 --ignore 跳过插入主键已存在的任何记录:
sqlite-utils insert dogs.db dogs dogs.json --pk=id --ignore
您可以使用 --truncate 在插入新记录之前删除表中的所有现有行:
sqlite-utils insert dogs.db dogs dogs.json --truncate
您可以添加 --analyze 选项,以便在插入行后对表运行 ANALYZE。
插入二进制数据¶
您可以通过先使用 base64 编码二进制数据,然后按照如下结构化来将其插入到 BLOB 列中:
[
{
"name": "transparent.gif",
"content": {
"$base64": true,
"encoded": "R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7"
}
}
]
插入换行符分隔的 JSON¶
您还可以使用 --nl 选项导入 换行符分隔的 JSON:
echo '{"id": 1, "name": "Cleo"}
{"id": 2, "name": "Suna"}' | sqlite-utils insert creatures.db creatures - --nl
换行符分隔的 JSON 由通过换行符分隔的完整 JSON 对象组成。
如果您使用 jq 处理数据,可以使用 jq -c 选项输出有效的换行符分隔的 JSON。
由于 Datasette 可以导出换行符分隔的 JSON,您可以将 Datasette 和 sqlite-utils 结合起来,如下所示:
curl -L "https://latest.datasette.io/fixtures/facetable.json?_shape=array&_nl=on" \
| sqlite-utils insert nl-demo.db facetable - --pk=id --nl
您还可以将 sqlite-utils 管道连接起来,以创建一个新的 SQLite 数据库文件,其中包含对另一个数据库的 SQL 查询结果:
sqlite-utils sf-trees.db \
"select TreeID, qAddress, Latitude, Longitude from Street_Tree_List" --nl \
| sqlite-utils insert saved.db trees - --nl
sqlite-utils saved.db "select * from trees limit 5" --csv
TreeID,qAddress,Latitude,Longitude
141565,501X Baker St,37.7759676911831,-122.441396661871
232565,940 Elizabeth St,37.7517102172731,-122.441498017841
119263,495X Lakeshore Dr,,
207368,920 Kirkham St,37.760210314285,-122.47073935813
188702,1501 Evans Ave,37.7422086702947,-122.387293152263
展平嵌套的 JSON 对象¶
sqlite-utils insert 和 sqlite-utils memory 都期望传入的 JSON 数据由 JSON 对象的数组组成,其中每个对象的顶级键将成为创建的数据库表中的列。
如果您的数据是嵌套的,可以使用 --flatten 选项创建从嵌套数据派生的列。
考虑以下示例文档,位于名为 log.json 的文件中:
{
"httpRequest": {
"latency": "0.112114537s",
"requestMethod": "GET",
"requestSize": "534",
"status": 200
},
"insertId": "6111722f000b5b4c4d4071e2",
"labels": {
"service": "datasette-io"
}
}
使用 sqlite-utils insert logs.db logs log.json 将其插入表中将创建具有以下 schema 的表:
CREATE TABLE [logs] (
[httpRequest] TEXT,
[insertId] TEXT,
[labels] TEXT
);
使用 --flatten 选项,将使用 topkey_nextkey 列名创建列 - 因此运行 sqlite-utils insert logs.db logs log.json --flatten 将创建以下 schema:
CREATE TABLE [logs] (
[httpRequest_latency] TEXT,
[httpRequest_requestMethod] TEXT,
[httpRequest_requestSize] TEXT,
[httpRequest_status] INTEGER,
[insertId] TEXT,
[labels_service] TEXT
);
插入 CSV 或 TSV 数据¶
如果您的数据是 CSV 格式,可以使用 --csv 选项插入:
sqlite-utils insert dogs.db dogs dogs.csv --csv
对于 Tab 分隔数据,使用 --tsv:
sqlite-utils insert dogs.db dogs dogs.tsv --tsv
数据应以 Unicode UTF-8 编码。如果您的数据是另一种字符编码,可以使用 --encoding 选项指定:
sqlite-utils insert dogs.db dogs dogs.tsv --tsv --encoding=latin-1
要在指定数量的记录后停止插入 - 这对于更快地预览大文件很有用 - 使用 --stop-after 选项:
sqlite-utils insert dogs.db dogs dogs.csv --csv --stop-after=10
从文件插入数据时会显示进度条。您可以使用 --silent 选项隐藏进度条。
默认情况下,从 CSV 或 TSV 文件插入的每个列都将是 TEXT 类型。要自动检测列类型 - 生成 TEXT、INTEGER 和 FLOAT 列的混合 - 使用 --detect-types 选项(或其快捷方式 -d)。
例如,给定一个包含以下内容的 creatures.csv 文件:
name,age,weight
Cleo,6,45.5
Dori,1,3.5
以下命令:
sqlite-utils insert creatures.db creatures creatures.csv --csv --detect-types
将生成此 schema:
sqlite-utils schema creatures.db
CREATE TABLE "creatures" (
[name] TEXT,
[age] INTEGER,
[weight] FLOAT
);
如果您希望 --detect-types 成为默认行为,可以设置 SQLITE_UTILS_DETECT_TYPES 环境变量:
export SQLITE_UTILS_DETECT_TYPES=1
如果 CSV 或 TSV 文件包含空单元格,例如这个:
name,age,weight
Cleo,6,
Dori,,3.5
它们将被导入到 SQLite 中,作为空字符串值,即 ""。
要将它们导入为 NULL 值,请使用 --empty-null 选项:
sqlite-utils insert creatures.db creatures creatures.csv --csv --empty-null
替代分隔符和引用字符¶
如果您的文件使用 , 以外的分隔符或 " 以外的引用字符,您可以尝试检测分隔符或显式指定它们。
--sniff 选项可用于尝试检测分隔符:
sqlite-utils insert dogs.db dogs dogs.csv --sniff
或者,您可以使用 --delimiter 和 --quotechar 选项指定它们。
这是一个使用 ; 作为分隔符和 | 符号作为引用字符的 CSV 文件:
name;description
Cleo;|Very fine; a friendly dog|
Pancakes;A local corgi
您可以使用以下命令导入它:
sqlite-utils insert dogs.db dogs dogs.csv --delimiter=";" --quotechar="|"
传递 --delimiter、--quotechar 或 --sniff 意味着 --csv,因此您可以省略 --csv 选项。
没有 header 行的 CSV 文件¶
任何 CSV 或 TSV 文件的第一行应包含该文件中列的名称。
如果您的文件不包含此行,您可以使用 --no-headers 选项指定工具不应将第一行用作标题。
如果您这样做,将创建表并使用名为 untitled_1、untitled_2 等的列名。然后可以使用 sqlite-utils transform ... --rename 命令重命名它们,参见转换表。
使用 --lines 和 --text 插入非结构化数据¶
如果您有一个非结构化文件,可以使用 --lines 将其内容插入到只有一个 line 列的表中,该列包含文件中的每一行。如果您打算使用 SQL 字符串函数或 sqlite-utils convert 进一步分析这些行,这可能很有用:
sqlite-utils insert logs.db loglines logfile.log --lines
这将生成以下 schema:
CREATE TABLE [loglines] (
[line] TEXT
);
您还可以使用 --text 将文件的全部内容插入到名为 text 的单个列中:
sqlite-utils insert content.db content file.txt --text
这里的 schema 将是:
CREATE TABLE [content] (
[text] TEXT
);
插入数据时应用转换¶
--convert 选项可用于在将导入的数据插入到数据库之前对其应用 Python 转换函数。其工作方式类似于 sqlite-utils convert。
您的 Python 函数将传递一个名为 row 的字典,用于正在导入的每个项。您可以修改该字典并返回它 - 或返回一个新的字典 - 以更改将要插入的数据。
给定一个名为 dogs.json 的 JSON 文件,其中包含以下内容:
[
{"id": 1, "name": "Cleo"},
{"id": 2, "name": "Pancakes"}
]
以下命令将插入该数据,并为每只狗添加一个设置为 1 的 is_good 列:
sqlite-utils insert dogs.db dogs dogs.json --convert 'row["is_good"] = 1'
--convert 选项也适用于 --csv、--tsv 和 --nl 插入选项。
与 sqlite-utils convert 一样,您可以使用 --import 导入额外的 Python 模块,详情请参阅导入额外的模块。
您还可以传递运行一些初始化步骤并定义 convert(value) 函数的代码,参见定义 convert() 函数。
--convert 结合 --lines 使用¶
与 --lines 或 --text 选项结合使用时,工作方式略有不同。
使用 --lines 时,您的函数将传递一个 line 字符串,表示输入的每一行,而不是传递一个 row 字典。给定一个名为 access.log 的文件,其中包含以下内容:
INFO: 127.0.0.1:60581 - GET / HTTP/1.1 200 OK
INFO: 127.0.0.1:60581 - GET /foo/-/static/app.css?cead5a HTTP/1.1 200 OK
您可以将其转换为结构化数据,如下所示:
sqlite-utils insert logs.db loglines access.log --convert '
type, source, _, verb, path, _, status, _ = line.split()
return {
"type": type,
"source": source,
"verb": verb,
"path": path,
"status": status,
}' --lines
生成的表将如下所示:
type |
source |
verb |
path |
status |
|---|---|---|---|---|
INFO |
127.0.0.1:60581 |
GET |
/ |
200 |
INFO |
127.0.0.1:60581 |
GET |
/foo/-/static/app.css?cead5a |
200 |
--convert 结合 --text 使用¶
使用 --text 时,整个命令输入将作为名为 text 的变量提供给函数。
该函数可以返回一个字典,它将作为单行插入;也可以返回一个字典列表或迭代器,每个都将被插入。
以下是如何使用 --convert 和 --text 为输入中的每个单词插入一条记录:
echo 'A bunch of words' | sqlite-utils insert words.db words - \
--text --convert '({"word": w} for w in text.split())'
结果如下所示:
sqlite-utils dump words.db
BEGIN TRANSACTION;
CREATE TABLE [words] (
[word] TEXT
);
INSERT INTO "words" VALUES('A');
INSERT INTO "words" VALUES('bunch');
INSERT INTO "words" VALUES('of');
INSERT INTO "words" VALUES('words');
COMMIT;
插入替换数据¶
insert 命令的 --replace 选项会导致任何具有相同主键的现有记录完全被新记录替换。
要用新记录替换 ID 为 2 的狗,请运行以下命令:
echo '{"id": 2, "name": "Pancakes", "age": 3}' | \
sqlite-utils insert dogs.db dogs - --pk=id --replace
Upsert 数据¶
Upsert 是更新或插入。如果存在具有指定主键的行,将更新提供的列。如果不存在行,将创建该行。
与 insert --replace 不同,upsert 将忽略存在但未在 upsert 文档中出现的任何列值。
例如:
echo '{"id": 2, "age": 4}' | \
sqlite-utils upsert dogs.db dogs - --pk=id
这将更新 ID 为 2 的狗,将其年龄设置为 4,如果不存在,则创建一个新记录(名称为 null)。如果行确实存在,名称将保持不变。
如果您引用的列在表中不存在,命令将失败。要自动创建缺失的列,请使用 --alter 选项。
注意
sqlite-utils 1.x 中的 upsert 工作方式类似于 2.x 中的 insert ... --replace。有关此更改的详细信息,请参阅 issue #66。
批量执行 SQL¶
如果您有 JSON、换行符分隔的 JSON、CSV 或 TSV 文件,可以使用 sqlite-utils bulk 命令使用该文件中的每条记录批量执行 SQL 查询。
该命令接受数据库文件、要执行的 SQL 以及包含用于评估 SQL 查询的记录的文件。
SQL 查询应包含与记录中键匹配的 :named 参数。
例如,给定一个包含以下内容的 chickens.csv CSV 文件:
id,name
1,Blue
2,Snowy
3,Azi
4,Lila
5,Suna
6,Cardi
您可以将这些行插入到预先创建的 chickens 表中,如下所示:
sqlite-utils bulk chickens.db \
'insert into chickens (id, name) values (:id, :name)' \
chickens.csv --csv
此命令接受与 sqlite-utils insert 命令相同的选项 - 因此默认情况下预期为 JSON,但可以使用 --csv 或 --tsv 或 --nl 或上面描述的其他选项接受其他格式。
默认情况下,所有 SQL 查询将在单个事务中执行。要每 20 条记录提交一次,请使用 --batch-size 20。
从文件插入数据¶
insert-files 命令可用于将文件的内容及其元数据插入到 SQLite 表中。
以下是将当前目录中所有 GIF 文件插入到 gifs.db 数据库中,并将文件内容放入 images 表的示例:
sqlite-utils insert-files gifs.db images *.gif
您还可以传递一个或多个目录,在这种情况下,这些目录中的每个文件都将递归添加:
sqlite-utils insert-files gifs.db images path/to/my-gifs
默认情况下,此命令将创建具有以下 schema 的表:
CREATE TABLE [images] (
[path] TEXT PRIMARY KEY,
[content] BLOB,
[size] INTEGER
);
内容默认将被视为二进制数据,并存储在 BLOB 列中。您可以使用 --text 选项将内容存储在 TEXT 列中。
您可以使用一个或多个 -c 选项自定义 schema。对于仅包含文件路径、MD5 哈希和最后修改时间的表 schema,您将使用以下命令:
sqlite-utils insert-files gifs.db images *.gif -c path -c md5 -c mtime --pk=path
这将产生以下 schema:
CREATE TABLE [images] (
[path] TEXT PRIMARY KEY,
[md5] TEXT,
[mtime] FLOAT
);
请注意,这里根本没有 content 列 - 如果您使用 -c 指定自定义列,则需要包含 -c content 来创建该列。
您可以使用 -c colname:coldef 参数更改其中一列的名称。要将 mtime 列重命名为 last_modified,您将使用以下命令:
sqlite-utils insert-files gifs.db images *.gif \
-c path -c md5 -c last_modified:mtime --pk=path
您可以传递 --replace 或 --upsert 来指示尝试插入具有现有主键的文件时应发生什么。传递 --alter 以使任何缺失的列添加到表中。
可以使用的列定义完整列表如下:
name文件名称,例如
cleo.jpgpath文件相对于根文件夹的路径,例如
pictures/cleo.jpgfullpath图像的完全解析路径,例如
/home/simonw/pictures/cleo.jpgsha256文件内容的 SHA256 哈希
md5文件内容的 MD5 哈希
mode文件的权限位,以整数表示 - 您可能需要将其转换为八进制
content二进制文件内容,将存储为 BLOB
content_text文本文件内容,将存储为 TEXT
mtime文件修改时间,以 Unix 纪元以来的浮点秒数表示
ctime文件创建时间,以 Unix 纪元以来的浮点秒数表示
mtime_int修改时间,以整数而不是浮点数表示
ctime_int创建时间,以整数而不是浮点数表示
mtime_iso修改时间,以 ISO 时间戳格式表示,例如
2020-07-27T04:24:06.654246ctime_iso创建时间,以 ISO 时间戳格式表示
size文件大小(以字节为单位)的整数
stem不带扩展名的文件名 - 对于
file.txt.gz,这将是file.txtsuffix文件扩展名 - 对于
file.txt.gz,这将是.gz
您可以像这样插入从标准输入管道传递的数据:
cat dog.jpg | sqlite-utils insert-files dogs.db pics - --name=dog.jpg
- 参数表示应从标准输入读取数据。使用 --name 选项传递的字符串将用于文件名和路径值。
从标准输入插入数据时,仅支持以下列定义:name、path、content、content_text、sha256、md5 和 size。
转换列中的数据¶
convert 命令可用于转换指定列中的数据 - 例如,将日期字符串解析为 ISO 时间戳,或将标签字符串拆分为 JSON 数组。
该命令接受一个数据库、表、一个或多个列以及一段 Python 代码,该代码将对这些列中的值执行。以下示例将 articles 表中 headline 列的值替换为大写版本:
sqlite-utils convert content.db articles headline 'value.upper()'
Python 代码作为字符串传递。在该 Python 代码中,value 变量将是当前列的值。
您提供的代码将被编译成一个接受 value 作为单个参数的函数。如果您的函数体分为多行,则最后一行应该是 return 语句:
sqlite-utils convert content.db articles headline '
value = str(value)
return value.upper()'
您的代码将自动包装在一个函数中,但您也可以定义一个名为 convert(value) 的函数,如果可用,该函数将被调用:
sqlite-utils convert content.db articles headline '
def convert(value):
return value.upper()'
使用 - 作为 CODE 值从标准输入读取:
cat mycode.py | sqlite-utils convert content.db articles headline -
其中 mycode.py 包含一个如下所示的 Python 代码片段:
def convert(value):
return value.upper()
转换将应用于指定表中的每一行。您可以使用 --where 将其限制为仅与 WHERE 子句匹配的行:
sqlite-utils convert content.db articles headline 'value.upper()' \
--where "headline like '%cat%'"
您可以在 where 子句中包含命名参数,并使用一个或多个 --param 选项填充它们:
sqlite-utils convert content.db articles headline 'value.upper()' \
--where "headline like :query" \
--param query '%cat%'
--dry-run 选项将输出前十行的转换预览,而不会修改数据库。
默认情况下,对于列值为假(如 0 或 null)的任何行,都将跳过。使用 --no-skip-false 选项禁用此行为。
导入额外的模块¶
您可以使用一个或多个 --import 选项指定应导入并提供给您的代码的 Python 模块。此示例使用 textwrap 模块将 content 列包装为 100 个字符:
sqlite-utils convert content.db articles content \
'"\n".join(textwrap.wrap(value, 100))' \
--import=textwrap
这也支持嵌套导入,例如使用 ElementTree:
sqlite-utils convert content.db articles content \
'xml.etree.ElementTree.fromstring(value).attrib["title"]' \
--import=xml.etree.ElementTree
使用调试器¶
如果在运行转换操作时发生错误,您可能会看到如下消息:
user-defined function raised exception
添加 --pdb 选项以捕获错误并在该点打开 Python 调试器。在调试器中键入 q 后,转换操作将退出。
这是一个示例调试会话。首先,创建一个 articles 表,其 content 列包含无效 XML:
echo '{"content": "This is not XML"}' | sqlite-utils insert content.db articles -
现在使用 --pdb 选项运行转换:
sqlite-utils convert content.db articles content \
'xml.etree.ElementTree.fromstring(value).attrib["title"]' \
--import=xml.etree.ElementTree \
--pdb
发生错误时,调试器将打开:
Exception raised, dropping into pdb...: syntax error: line 1, column 0
> .../python3.11/xml/etree/ElementTree.py(1338)XML()
-> parser.feed(text)
(Pdb) args
text = 'This is not XML'
parser = <xml.etree.ElementTree.XMLParser object at 0x102c405e0>
(Pdb) q
这里的 args 显示堆栈中当前函数的参数。Python pdb documentation 包含其他可用命令的完整详细信息。
定义 convert() 函数¶
您可以定义一个名为 convert(value) 的函数,而不是提供要对每个值执行的单行代码。
这种机制可用于执行一次性的初始化代码,该代码在转换运行开始时运行一次。
以下示例添加了一个新的 score 列,然后将其更新为列出一个随机数 - 首先设置随机数生成器的种子,以确保多次运行产生相同的结果:
sqlite-utils add-column content.db articles score float --not-null-default 1.0
sqlite-utils convert content.db articles score '
import random
random.seed(10)
def convert(value):
return random.random()
'
sqlite-utils convert 示例¶
对于常见操作,可以使用各种内置示例函数。这些包括:
r.jsonsplit(value, delimiter=',', type=<class 'str'>)将字符串(如
a,b,c)转换为 JSON 数组["a", "b", "c"]。delimiter参数可用于指定不同的分隔符。type参数可以设置为float或int以生成不同类型的 JSON 数组,例如,如果列的字符串值为1.2,3,4.5,则以下命令:r.jsonsplit(value, type=float)
将生成如下数组:
[1.2, 3.0, 4.5]r.parsedate(value, dayfirst=False, yearfirst=False, errors=None)解析日期并将其转换为 ISO 日期格式:
yyyy-mm-dd对于诸如
03/04/05之类的日期,假定为美国MM/DD/YY格式 - 您可以使用dayfirst=True或yearfirst=True来更改如何解释这些不明确的日期。使用
errors=参数指定如果某个值无法解析时应发生什么。默认情况下,如果任何值无法解析,将发生错误,并且所有值将保持不变。
设置
errors=r.IGNORE以忽略任何无法解析的值,使其保持不变。设置
errors=r.SET_NULL,将任何无法解析的值设置为null。r.parsedatetime(value, dayfirst=False, yearfirst=False, errors=None)解析日期时间并将其转换为 ISO 日期时间格式:
yyyy-mm-ddTHH:MM:SS
这些用法可以在传递给 sqlite-utils convert 的代码中使用,如下所示
sqlite-utils convert my.db mytable mycolumn \
'r.jsonsplit(value)'
要使用任何文档中提到的参数,请这样做
sqlite-utils convert my.db mytable mycolumn \
'r.jsonsplit(value, delimiter=":")'
将结果保存到不同的列¶
可以使用 --output 和 --output-type 选项将转换结果保存到单独的列中,如果该列尚不存在,则将创建它
sqlite-utils convert content.db articles headline 'value.upper()' \
--output headline_upper
创建的列的类型默认为 text,但可以使用 --output-type 指定不同的列类型。此示例将创建一个名为 id_as_a_float 的新的浮点数列,其中包含每个项目 ID 增加 0.5 后的副本
sqlite-utils convert content.db articles id 'float(value) + 0.5' \
--output id_as_a_float \
--output-type float
通过添加 --drop,可以在操作结束时删除原始列。
将一列转换为多列¶
有时您可能希望将单列转换为多个派生列。例如,您可能有一个 location 列,其中包含 latitude,longitude 值,您希望将其拆分为单独的 latitude 和 longitude 列。
您可以使用 sqlite-utils convert 的 --multi 选项来实现此目的。此选项要求您的 Python 代码返回一个 Python 字典:将为该字典中的每个键创建和填充新列。
对于 latitude,longitude 示例,您将使用以下内容
sqlite-utils convert demo.db places location \
'bits = value.split(",")
return {
"latitude": float(bits[0]),
"longitude": float(bits[1]),
}' --multi
在创建新列时,将考虑返回值的数据类型。在此示例中,生成的数据库 schema 将如下所示
CREATE TABLE [places] (
[location] TEXT,
[latitude] FLOAT,
[longitude] FLOAT
);
代码函数也可以返回 None,在这种情况下其输出将被忽略。通过添加 --drop,可以在操作结束时删除原始列。
创建表¶
大多数情况下,通过插入示例数据来创建表是最快的方法。如果您需要在插入数据之前提前创建一个空表,可以使用 create-table 命令来实现
sqlite-utils create-table mydb.db mytable id integer name text --pk=id
这将创建一个名为 mytable 的表,其中包含两列 - 一个整数 id 列和一个文本 name 列。它会将 id 列设置为主键。
您可以根据需要传递任意数量的列名-列类型对。有效类型包括 integer、text、float 和 blob。
对于覆盖多个列的复合主键,请多次传递 --pk。
您可以使用 --not-null colname 指定应为 NOT NULL 的列。您可以使用 --default colname defaultvalue 为列指定默认值。
sqlite-utils create-table mydb.db mytable \
id integer \
name text \
age integer \
is_good integer \
--not-null name \
--not-null age \
--default is_good 1 \
--pk=id
sqlite-utils tables mydb.db --schema -t
table schema
------- --------------------------------
mytable CREATE TABLE [mytable] (
[id] INTEGER PRIMARY KEY,
[name] TEXT NOT NULL,
[age] INTEGER NOT NULL,
[is_good] INTEGER DEFAULT '1'
)
您可以使用 --fk colname othertable othercolumn 指定您正在创建的表之间的外键关系
sqlite-utils create-table books.db authors \
id integer \
name text \
--pk=id
sqlite-utils create-table books.db books \
id integer \
title text \
author_id integer \
--pk=id \
--fk author_id authors id
sqlite-utils tables books.db --schema -t
table schema
------- -------------------------------------------------
authors CREATE TABLE [authors] (
[id] INTEGER PRIMARY KEY,
[name] TEXT
)
books CREATE TABLE [books] (
[id] INTEGER PRIMARY KEY,
[title] TEXT,
[author_id] INTEGER REFERENCES [authors]([id])
)
您可以使用 --strict 在 SQLite STRICT 模式 下创建表
sqlite-utils create-table mydb.db mytable id integer name text --strict
sqlite-utils tables mydb.db --schema -t
table schema
------- ------------------------
mytable CREATE TABLE [mytable] (
[id] INTEGER,
[name] TEXT
) STRICT
如果已存在同名表,您将收到错误。您可以选择使用 --ignore 静默忽略此错误,或者使用 --replace 将现有表替换为一个新的空表。
您也可以传递 --transform 来转换现有表以匹配新的 schema。有关此选项如何工作的详细信息,请参阅 Python 库文档中的明确创建表。
重命名表¶
您可以使用 rename-table 命令重命名表
sqlite-utils rename-table mydb.db oldname newname
传递 --ignore 以忽略由表不存在或新名称已被使用引起的任何错误。
复制表¶
duplicate 命令会复制一个表 - 创建一个具有相同 schema 并包含所有行副本的新表
sqlite-utils duplicate books.db authors authors_copy
删除表¶
您可以使用 drop-table 命令删除表
sqlite-utils drop-table mydb.db mytable
如果表不存在,使用 --ignore 忽略错误。
转换表¶
transform 命令允许您对表应用复杂的转换,这些转换无法使用常规的 SQLite ALTER TABLE 命令实现。有关其工作原理的详细信息,请参阅转换表。 transform 命令会保留表的 STRICT 模式。
sqlite-utils transform mydb.db mytable \
--drop column1 \
--rename column2 column_renamed
此表的所有选项(除了 --pk-none)都可以多次指定。选项如下:
--type column-name new-type更改指定列的类型。有效类型包括
integer、text、float、blob。--drop column-name删除指定列。
--rename column-name new-name将此列重命名为新名称。
--column-order column多次使用此选项可为您的列指定新顺序。也可以使用
-o快捷方式。--not-null column-name将此列设置为
NOT NULL。--not-null-false column-name对于当前设置为
NOT NULL的列,移除NOT NULL。--pk column-name更改此表的主键列。如果需要创建复合主键,请多次传递
--pk。--pk-none从此表中移除主键,将其转换为
rowid表。--default column-name value设置此列的默认值。
--default-none column移除此列的默认值。
--drop-foreign-key column删除指定外键。
--add-foreign-key column other_table other_column为
column添加一个外键约束,指向other_table.other_column。
如果您想查看将执行的 SQL 而不是实际执行它,请添加 --sql 标志。例如:
sqlite-utils transform fixtures.db roadside_attractions \
--rename pk id \
--default name Untitled \
--column-order id \
--column-order longitude \
--column-order latitude \
--drop address \
--sql
CREATE TABLE [roadside_attractions_new_4033a60276b9] (
[id] INTEGER PRIMARY KEY,
[longitude] FLOAT,
[latitude] FLOAT,
[name] TEXT DEFAULT 'Untitled'
);
INSERT INTO [roadside_attractions_new_4033a60276b9] ([longitude], [latitude], [id], [name])
SELECT [longitude], [latitude], [pk], [name] FROM [roadside_attractions];
DROP TABLE [roadside_attractions];
ALTER TABLE [roadside_attractions_new_4033a60276b9] RENAME TO [roadside_attractions];
为 rowid 表添加主键¶
未明确指定主键创建的 SQLite 表会创建为 rowid 表。它们仍然有一个数字主键,该主键可在 rowid 列中获取,但该列不包含在 select * 的输出中。示例如下:
echo '[{"name": "Azi"}, {"name": "Suna"}]' | \
sqlite-utils insert chickens.db chickens -
sqlite-utils schema chickens.db
CREATE TABLE [chickens] (
[name] TEXT
);
sqlite-utils chickens.db 'select * from chickens'
[{"name": "Azi"},
{"name": "Suna"}]
sqlite-utils chickens.db 'select rowid, * from chickens'
[{"rowid": 1, "name": "Azi"},
{"rowid": 2, "name": "Suna"}]
您可以使用 sqlite-utils transform ... --pk id 为表添加一个名为 id 的主键列。主键将创建为 INTEGER PRIMARY KEY,并且现有的 rowid 值将被复制到其中。随着新行添加到表中,它将自动递增
sqlite-utils transform chickens.db chickens --pk id
sqlite-utils schema chickens.db
CREATE TABLE "chickens" (
[id] INTEGER PRIMARY KEY,
[name] TEXT
);
sqlite-utils chickens.db 'select * from chickens'
[{"id": 1, "name": "Azi"},
{"id": 2, "name": "Suna"}]
echo '{"name": "Cardi"}' | sqlite-utils insert chickens.db chickens -
sqlite-utils chickens.db 'select * from chickens'
[{"id": 1, "name": "Azi"},
{"id": 2, "name": "Suna"},
{"id": 3, "name": "Cardi"}]
将列提取到单独的表中¶
sqlite-utils extract 命令可用于将指定列提取到单独的表中。
请参阅 Python API 文档中关于将列提取到单独的表中的部分,以获取关于其工作原理的详细说明,包括运行提取操作前后的表 schema 示例。
该命令接受一个数据库、一个表和一个或多个应提取的列。要从 trees 表中提取 species 列,您可以运行
sqlite-utils extract my.db trees species
这将生成以下 schema
CREATE TABLE "trees" (
[id] INTEGER PRIMARY KEY,
[TreeAddress] TEXT,
[species_id] INTEGER,
FOREIGN KEY(species_id) REFERENCES species(id)
);
CREATE TABLE [species] (
[id] INTEGER PRIMARY KEY,
[species] TEXT
);
CREATE UNIQUE INDEX [idx_species_species]
ON [species] ([species]);
该命令接受以下选项
--table TEXT用于将列提取到其中的查找表的名称。默认为使用正在提取的列的名称。
--fk-column TEXT要添加到表中的外键列的名称。默认为
columnname_id。--rename <TEXT TEXT>使用此选项重命名在新查找表中创建的列。
--silent不显示进度条。
这是一个使用这些选项的更复杂的示例。它将包含全球发电厂的此 CSV 文件转换为 SQLite,然后将 country 和 country_long 列提取到单独的 countries 表中
wget 'https://github.com/wri/global-power-plant-database/blob/232a6666/output_database/global_power_plant_database.csv?raw=true'
sqlite-utils insert global.db power_plants \
'global_power_plant_database.csv?raw=true' --csv
# Extract those columns:
sqlite-utils extract global.db power_plants country country_long \
--table countries \
--fk-column country_id \
--rename country_long name
运行上述命令后,命令 sqlite-utils schema global.db 会显示以下 schema
CREATE TABLE [countries] (
[id] INTEGER PRIMARY KEY,
[country] TEXT,
[name] TEXT
);
CREATE TABLE "power_plants" (
[country_id] INTEGER,
[name] TEXT,
[gppd_idnr] TEXT,
[capacity_mw] TEXT,
[latitude] TEXT,
[longitude] TEXT,
[primary_fuel] TEXT,
[other_fuel1] TEXT,
[other_fuel2] TEXT,
[other_fuel3] TEXT,
[commissioning_year] TEXT,
[owner] TEXT,
[source] TEXT,
[url] TEXT,
[geolocation_source] TEXT,
[wepp_id] TEXT,
[year_of_capacity_data] TEXT,
[generation_gwh_2013] TEXT,
[generation_gwh_2014] TEXT,
[generation_gwh_2015] TEXT,
[generation_gwh_2016] TEXT,
[generation_gwh_2017] TEXT,
[generation_data_source] TEXT,
[estimated_generation_gwh] TEXT,
FOREIGN KEY([country_id]) REFERENCES [countries]([id])
);
CREATE UNIQUE INDEX [idx_countries_country_name]
ON [countries] ([country], [name]);
创建视图¶
您可以使用 create-view 命令创建视图
sqlite-utils create-view mydb.db version "select sqlite_version()"
sqlite-utils mydb.db "select * from version"
[{"sqlite_version()": "3.31.1"}]
使用 --replace 替换同名现有视图,如果视图已存在则使用 --ignore 不执行任何操作。
删除视图¶
您可以使用 drop-view 命令删除视图
sqlite-utils drop-view myview
如果视图不存在,使用 --ignore 忽略错误。
添加列¶
您可以使用 add-column 命令添加列
sqlite-utils add-column mydb.db mytable nameofcolumn text
这里的最后一个参数是要创建的列的类型。可以是以下之一:
text或strinteger或intfloatblob或bytes
此参数是可选的,默认为 text。
您可以使用 --fk 选项添加一个外键引用到另一个表的列
sqlite-utils add-column mydb.db dogs species_id --fk species
这将自动检测 species 表上的主键名称,并将其(及其类型)用于新列。
您可以使用 --fk-col 明确指定要引用的列
sqlite-utils add-column mydb.db dogs species_id --fk species --fk-col ref
您可以使用 --not-null-default 在新列上设置 NOT NULL DEFAULT 'x' 约束
sqlite-utils add-column mydb.db dogs friends_count integer --not-null-default 0
在插入/更新时自动添加列¶
如果您正在插入或 upsert 的数据形状不同,您可以使用 --alter 选项自动添加新列
sqlite-utils insert dogs.db dogs new-dogs.json --pk=id --alter
添加外键约束¶
add-foreign-key 命令可用于向现有表添加新的外键引用 - 这是 SQLite 的 ALTER TABLE 命令不支持的功能。
要添加一个外键约束,将 books.author_id 列指向另一个表中的 authors.id,请执行以下操作
sqlite-utils add-foreign-key books.db books author_id authors id
如果您省略了其他表和其他列引用,sqlite-utils 将尝试猜测它们 - 因此上面的示例可以改为这样
sqlite-utils add-foreign-key books.db books author_id
添加 --ignore 以忽略现有外键(而不是返回错误)
sqlite-utils add-foreign-key books.db books author_id --ignore
有关更多详细信息,包括自动表猜测机制的工作原理,请参阅 Python API 文档中的添加外键约束。
一次添加多个外键¶
添加外键需要 VACUUM。在大型数据库上,这可能是一个昂贵的操作,因此如果您要添加多个外键,可以使用 add-foreign-keys 将它们合并为一个操作(从而进行一次 VACUUM)
sqlite-utils add-foreign-keys books.db \
books author_id authors id \
authors country_id countries id
使用此命令时,每个外键都需要完整定义,作为四个参数 - 表、列、其他表和其他列。
为所有外键添加索引¶
如果您想确保数据库中的每个外键列都有相应的索引,可以这样做
sqlite-utils index-foreign-keys books.db
设置默认值和非空约束¶
您可以使用 --not-null 和 --default 选项(用于 insert 和 upsert)来指定应为 NOT NULL 的列,或为一列或多列设置数据库默认值
sqlite-utils insert dogs.db dogs_with_scores dogs-with-scores.json \
--not-null=age \
--not-null=name \
--default age 2 \
--default score 5
创建索引¶
您可以使用 create-index 命令向现有表添加索引
sqlite-utils create-index mydb.db mytable col1 [col2...]
这可用于针对单列或多列创建索引。
索引名称将根据表和列自动生成。要指定不同的名称,请使用 --name=name_of_index。
使用 --unique 选项创建唯一索引。
如果已存在同名索引,使用 --if-not-exists 可避免尝试创建。
要为列添加按降序排列的索引,请在列名前加上连字符。由于这可能与命令行选项混淆,您需要像这样构建它
sqlite-utils create-index mydb.db mytable -- col1 -col2 col3
这将在该表上创建 (col1, col2 desc, col3) 的索引。
如果您的列名已经以连字符开头,您需要手动执行 CREATE INDEX SQL 语句来添加索引,而不是使用此工具。
添加 --analyze 选项可在创建索引后对其运行 ANALYZE。
配置全文搜索¶
您可以像这样在表和一组列上启用 SQLite 全文搜索
sqlite-utils enable-fts mydb.db documents title summary
默认情况下,这将使用 SQLite 的 FTS5 模块。如果您想使用 FTS4,请使用 --fts4。
sqlite-utils enable-fts mydb.db documents title summary --fts4
enable-fts 命令将用所有现有文档填充新索引。如果您以后添加更多文档,则需要使用 populate-fts 来使其也被索引
sqlite-utils populate-fts mydb.db documents title summary
这里更好的解决方案是使用数据库触发器。您可以在首次运行 enable-fts 时使用 --create-triggers 选项设置数据库触发器,以便自动更新全文索引。
sqlite-utils enable-fts mydb.db documents title summary --create-triggers
要设置自定义 FTS 分词器,例如启用 Porter 词干提取,请使用 --tokenize=。
sqlite-utils populate-fts mydb.db documents title summary --tokenize=porter
要移除您创建的 FTS 表和触发器,请使用 disable-fts。
sqlite-utils disable-fts mydb.db documents
要重建一个或多个 FTS 表(参阅重建全文搜索表),请使用 rebuild-fts。
sqlite-utils rebuild-fts mydb.db documents
您可以在不传递任何表名的情况下运行 rebuild-fts 来重建所有 FTS 表。
sqlite-utils rebuild-fts mydb.db
执行搜索¶
为表配置全文搜索后,您可以使用 sqlite-utils search 进行搜索
sqlite-utils search mydb.db documents searchterm
此命令接受与 sqlite-utils query 相同的输出选项: --table、--csv、--tsv、--nl 等。
默认情况下,它首先显示最相关的匹配项。您可以使用 -o 选项指定不同的排序顺序,该选项可以接受列名或后跟 desc 的列名
# Sort by rowid
sqlite-utils search mydb.db documents searchterm -o rowid
# Sort by created in descending order
sqlite-utils search mydb.db documents searchterm -o 'created desc'
默认启用 SQLite 高级搜索语法。要运行对搜索词应用自动引号以避免它们可能被解释为高级搜索语法的搜索,请使用 --quote 选项。
您可以使用 -c 选项一次或多次指定要返回的列子集
sqlite-utils search mydb.db documents searchterm -c title -c created
默认情况下将返回所有搜索结果。您可以使用 --limit 20 只返回前 20 个结果。
使用 --sql 选项输出将要执行的 SQL,而不是运行查询
sqlite-utils search mydb.db documents searchterm --sql
with original as (
select
rowid,
*
from [documents]
)
select
[original].*
from
[original]
join [documents_fts] on [original].rowid = [documents_fts].rowid
where
[documents_fts] match :query
order by
[documents_fts].rank
启用缓存计数¶
select count(*) 查询在大型表上可能需要很长时间。sqlite-utils 可以通过添加触发器来维护一个 _counts 表来加快这些查询,详情请参阅使用触发器缓存表计数。
sqlite-utils enable-counts 命令可用于配置这些触发器,既可以针对数据库中的所有表,也可以针对特定表。
# Configure triggers for every table in the database
sqlite-utils enable-counts mydb.db
# Configure triggers just for specific tables
sqlite-utils enable-counts mydb.db table1 table2
如果 _counts 表与实际表计数不同步,您可以使用 reset-counts 命令修复它
sqlite-utils reset-counts mydb.db
使用 ANALYZE 优化索引使用¶
SQLite ANALYZE 命令构建一个统计表,查询规划器可以使用该表更好地决定为给定查询使用哪个索引。
如果您的数据库很大且您认为索引使用效率不高,则应该运行 ANALYZE。
要针对数据库中的每个索引运行 ANALYZE,请使用此命令
sqlite-utils analyze mydb.db
您可以通过将其作为可选参数传递,来针对特定表或特定命名索引运行它。
sqlite-utils analyze mydb.db mytable idx_mytable_name
您也可以使用 --analyze 选项将其作为另一个命令的一部分运行 ANALYZE。 create-index、insert 和 upsert 命令支持此功能。
Vacuum¶
您可以运行 VACUUM 来优化数据库,如下所示
sqlite-utils vacuum mydb.db
Optimize¶
如果您使用 SQLite 全文搜索,optimize 命令可以显著减小数据库的大小。它会对所有 FTS4 和 FTS5 表运行 OPTIMIZE,然后运行 VACUUM。
如果您只想运行 OPTIMIZE 而不进行 VACUUM,请使用 --no-vacuum 标志。
# Optimize all FTS tables and then VACUUM
sqlite-utils optimize mydb.db
# Optimize but skip the VACUUM
sqlite-utils optimize --no-vacuum mydb.db
要优化特定表而不是所有 FTS 表,请将这些表作为额外参数传递
sqlite-utils optimize mydb.db table_1 table_2
WAL 模式¶
您可以使用 enable-wal 命令为数据库文件启用预写式日志 (WAL)
sqlite-utils enable-wal mydb.db
您可以使用 disable-wal 禁用 WAL 模式
sqlite-utils disable-wal mydb.db
这两个命令都接受一个或多个数据库文件作为参数。
将数据库导出为 SQL¶
dump 命令输出指定数据库文件的 schema 和全部内容的 SQL 导出
sqlite-utils dump mydb.db
BEGIN TRANSACTION;
CREATE TABLE ...
...
COMMIT;
加载 SQLite 扩展¶
这些命令中的许多都可以使用 --load-extension=/path/to/extension 选项加载额外的 SQLite 扩展 - 使用 --help 检查支持情况,例如 sqlite-utils rows --help。
可以多次应用此选项以加载多个扩展。
由于 SpatiaLite 常与 SQLite 一起使用,spatialite 这个值是特殊的:它会在最常见的安装位置搜索 SpatiaLite,省去您记住该模块确切位置的麻烦
sqlite-utils memory "select spatialite_version()" --load-extension=spatialite
[{"spatialite_version()": "4.3.0a"}]
SpatiaLite 助手¶
SpatiaLite 为 SQLite 添加了地理空间能力(类似于 PostGIS 构建于 PostgreSQL 之上)。SpatiaLite cookbook 是一个学习其可能功能的优秀资源。
您可以通过添加几何列将现有表转换为地理空间表,使用 sqlite-utils add-geometry-column 命令
sqlite-utils add-geometry-column spatial.db locations geometry --type POLYGON --srid 4326
在添加几何列之前,表(上面示例中的 locations)必须已经存在。先使用 sqlite-utils create-table,然后使用 add-geometry-column。
使用 --type 选项指定几何类型。默认情况下,add-geometry-column 使用通用的 GEOMETRY 类型,它适用于任何类型,尽管可能不受某些桌面 GIS 应用程序的支持。
允许八种(不区分大小写)类型
POINT
LINESTRING
POLYGON
MULTIPOINT
MULTILINESTRING
MULTIPOLYGON
GEOMETRYCOLLECTION
GEOMETRY
添加空间索引¶
添加几何列后,您可以通过添加空间索引来加快边界框查询的速度。
sqlite-utils create-spatial-index spatial.db locations geometry
有关如何使用空间索引的示例,请参阅这篇 SpatiaLite Cookbook 配方。
安装软件包¶
convert 命令以及 insert –convert 和 query –functions 选项可以提供一个 Python 脚本,该脚本可以从 sqlite-utils 环境中导入额外的模块。
您可以使用 sqlite-utils install <package> 直接将 PyPI 中的软件包安装到正确的环境中。这是 pip install 的一个包装。
sqlite-utils install beautifulsoup4
使用 -U 升级现有软件包。
卸载软件包¶
您可以使用 sqlite-utils uninstall <package> 卸载使用 sqlite-utils install 安装的软件包。
sqlite-utils uninstall beautifulsoup4
使用 -y 跳过确认请求。
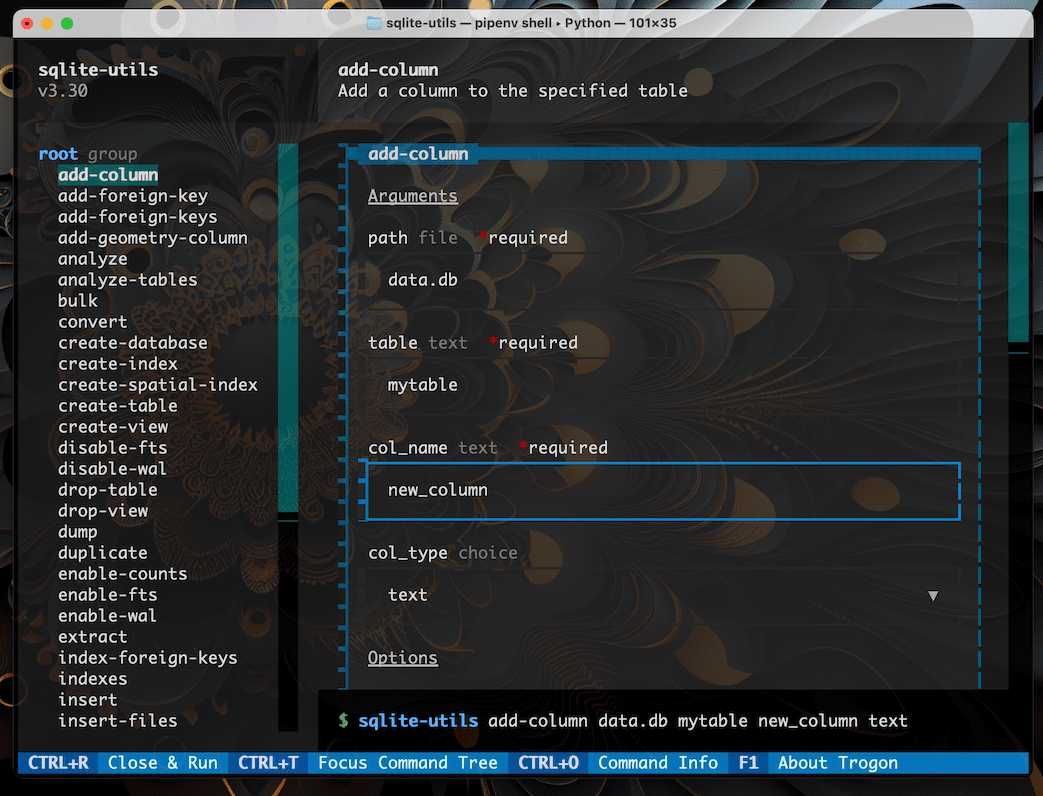
实验性 TUI¶
TUI 是“text user interface”(或“terminal user interface”)的缩写 - 它是一个在终端中运行的、由键盘和鼠标驱动的图形界面。
sqlite-utils 对构建命令行调用提供了实验性的 TUI 支持,它构建在 Trogon TUI 库之上。
要启用此功能,您需要安装 trogon 依赖项。您可以这样做
sqlite-utils install trogon
安装后,运行 sqlite-utils tui 命令将启动 TUI 界面。
sqlite-utils tui
然后,您可以通过从菜单中选择选项来构建命令,并使用 Ctrl+R 执行它。